The following images were made using DALL-E 2, a text-to-image AI generator by OpenAI. These are not the results of a Google search; none of these images existed before they were called into being. In all honestly, I have not encountered a image generator this intelligent before and I don’t really know what it means yet. More thoughts and feelings on the program in this post, although they’ve probably already developed since then. Here I’ll go into my few days using the bot and what I’ve learned.
First up is fantasy land art, a stitched-together, second-gen variation of this image.








































Various attempts at prompting hands holding silicone objects within a specific color palette. Search terms for greater customization included “Fujifilm film photo”, “Black hands” (as Open AI works through inherent biases in the data pool, white hands are the default), “light purple silicone mold of a manhole cover”, or “lilac silicone bike seat in the shape of a pegasus”.
These generations were entirely bot to bot. The text prompt was generated by a neural network AI, and the image on the left was a text-to-image translation of it I made in late 2021. The image on the right was made by generating variations of the original image.


“A pink case with a picture of a woman on the front. The case reads ‘Eileen’. Inside there are cigarettes that smell like dried roses.”
The variations feature was actually what excited me the most about using the program initially. I saw a video by Alan Resnik (he talks about it more on this Twitter thread) that is comprised of several images variating from a single prompt: “a bad photo”. These images above are variations of an image he produced from the program, more bot-to-bot communication.



While the initial resemblance can feel uncannily similar, with each generation the relationships begin to feel more tenuous. I also noticed that things began to smoothen. Photographs blur into 3D renders and never really return.


I tried to feed it with more ambiguous seed images, like this still from a video I made years ago. The results were quite diverse, and one variation led me down a path of people wearing strange pink-headed costumes and cotton tuft/snow-covered trees.







This is a series of hands holding a worm. The original image was found in a massive archive of scanned public domain book images on the Internet Archive’s Flickr account. It’s not linked because It was (tragically) deleted a couple of months ago.






I’m not sure why entirely but I found myself drawn towards generating hands.
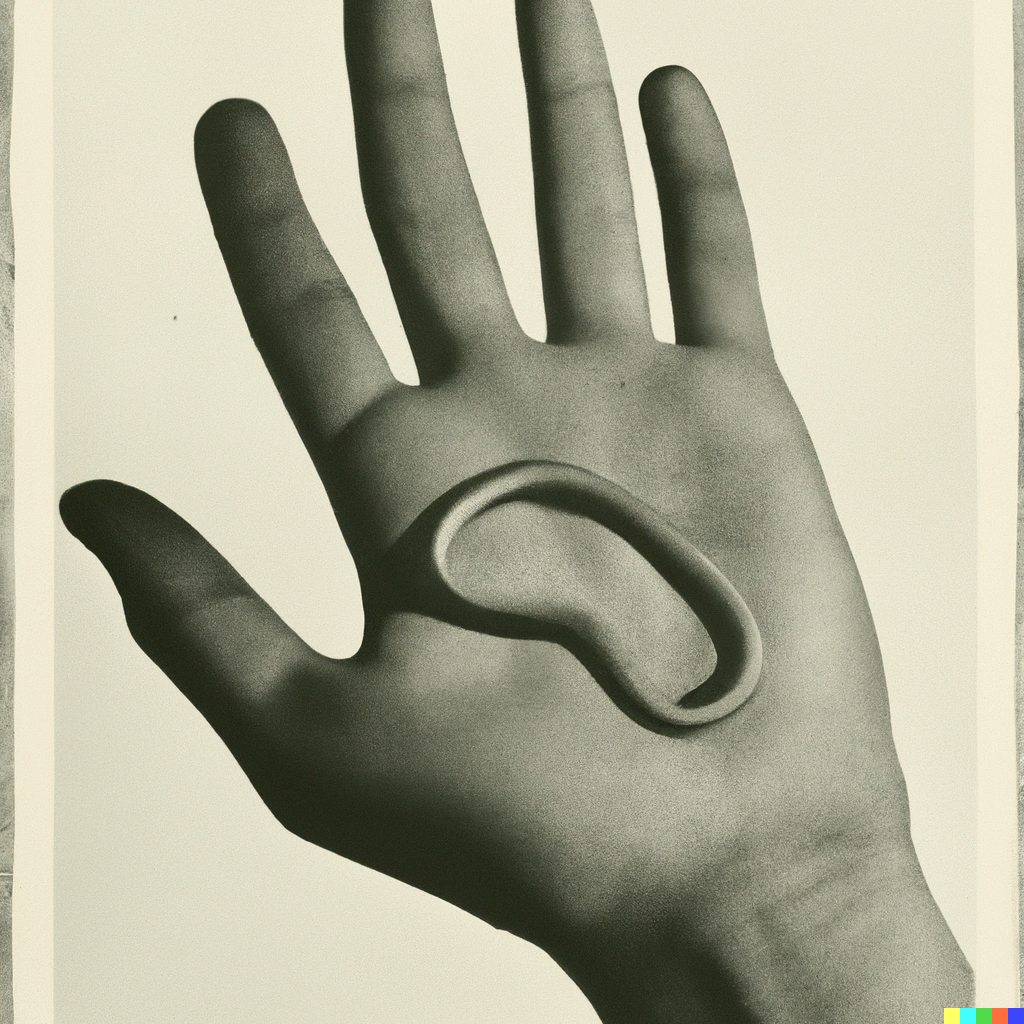




This source image generated the following images.


Hands holding lard.








The more I experimented with the program and communicated with others using it, I learned how to utilize keywords in prompts to generate images that approximated photographs. Clarifying the device such as a pinhole camera, disposable film, or CCTV; identifying colors like muted or pastel; clarifying the film stock like Fujifilm or Kodak; changing the shutter speed and depth of field, or stating a year or aesthetic era. While they’re both film, a photo taken in the 90s looks different than one taken in the 60s.
Variations of Bighorn Medicine Wheel, a streak of light, and hands kneading bread at a low shutter speed.


















A pinhole camera photo of a UFO flying over a field.

A truck is overgrown with weeds.



Variations of this album cover. (I don’t know this band, just love the image.)








A photo of a cow made out of gelatin with flowers embedded inside of it.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()









One of my former professors has a great collection of print ephemera that I pulled inspiration from for a few prompts. This series of images was originally variations of these but eventually, I used descriptions as prompts that would generate similar results. Some modifiers included “soft sculpture”, “wrapped in transparent plastic” or “reflective plastic”, “tied up with bungee cords” or “tape”.




























I also found some nice compositions. On the left, are variations of a spread I scanned from an old photography magazine. On the right, variations of a “wheat cross-stitch sampler” prompt.















Some prompts were more illustrative. For example, a 3D rendering of a purse made out of cake, that was inspired by this post.










3D renderings of No-Face from Studio Ghibli’s Spirited Away (2001) in a blooming wildflower meadow.
![]()
![]()
![]()
![]()
![]()
![]()






I learned from a Discord server of other DALL-E users how to stitch images together using the “in-painting” feature. Each “painting” is a series of images that were generated by matching the style of the original and adding new prompts with each generation.


Just as photographs became 3D renders in the above examples, paintbrush textures smooth, and fluorescent blue outlines start to appear around objects as they progress through the stitch.
These illustrations resulted from another still from this video with my morphsuit in its original chroma key blue.
![]()






And these are variations of Terr from Fantastic Planet (1973).


If you’ve made it this far, congrats. I hope some of this was interesting to you. I am still somewhat blown away at the specificity I’ve been able to produce with such ease. There’s something to it that is probably nefarious; a friend described it as instant gratification or a little bit of everything all of the time. I know I’ve felt joy, some derealization, and a jolt of creativity over the past few days as I play around. Ultimately this is a new tool that can and will be utilized in ways I can’t yet imagine, and perhaps I will feel different or more clear about that as the novelty wears off. For now, I will leave you with some miscellaneous images that didn’t fit above but I still liked them a lot.




